
はじめに
Summer'15からApex Connector FrameworkがDeveloper組織でも利用可能となりました。Apex Connector Frameworkとは、Lightning Connectの接続種別であるODataやSimple URLで外部データソースに接続できない場合の選択肢となるものです。Apex Connector Frameworkの仕様に則り外部データソースに対するConnectorをApexで実装することで、OData等で接続した場合と同様に外部のデータソースをあたかもSalesforceのオブジェクトとして参照する事が可能となります。
最近、別のLightningの話題はよく耳にするのですが、ことLightning Connectに関してはあまり話題にはのぼらず、以前このテーマで記事を書いた者としては少し寂しくなったので、今回実際にApex Connector Frameworkに触れてみて思ったことをプログラムを交えながら書いてみたいと思います。
試してみた事
Apex connector Frameworkを利用して下記の3つを試してみました。
①DynamoDBのデータをSalesforceのビューで表示
②DynamoDBのデータをSalesforceの参照画面で表示
③DynamoDBのデータ(実際にはCloudSearch上のデータ)に対してSalesforceのグローバル検索から全文検索
上記3つを実行した際の処理の流れから各種サービスの設定等を一つずつ説明していきます。
処理の流れ
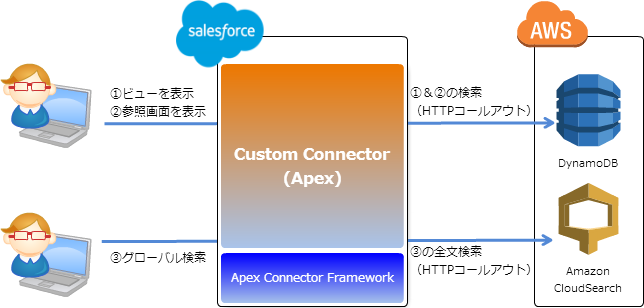
事前にSalesforce上で適切な設定やApexによる実装が必要になりますが、大まかな処理の流れは下記の通りです。
まず、ビューや参照画面の表示、そしてグローバル検索等を実行した場合にApex Connector Frameworkを通してApexで実装したConnectorが呼び出されます。
そして、ConnectorからコールアウトしてDynamoDBやCloudSearchのAPIを叩いて得た結果をApex Connector Frameworkに戻すと、Salesforceの画面に検索結果として表示されます。
ちなみにDynamoDBは全文検索を行う事ができませんので、全文検索はCloudSearchを利用して実現しています。
ですので、Salesforceでビューと参照画面を表示する場合はDynamoDBのAPIを叩き、グローバル検索を実行した場合はCloudSearchのAPIを叩くように処理を分岐しています。
それでは実際に設定した内容や実装内容を紹介していきます。
データの準備(DynamoDB)
何はともあれデータの準備です。
今回はDynamoDBに別システムから登録された問合せのデータが存在すると仮定し、かなり手抜きですが下記のようなデータを用意しました。
データの準備(CloudSearch)
次にCloudSearchの準備です。
Salesforce上でビューや参照画面を表示するだけであればDynamoDBにデータを準備してAPI叩けばOKなのですが、Apex Connector Frameworkはグローバル検索も対応しているので、せっかくだから全文検索もしちゃおうと思います。
ただ、DynamoDBはKey-Value型のNoSQLで、基本的にプライマリキーによる検索を行う(別途インデックスを作成すればプライマリキー以外の項目による絞り込みも可能)、もしくは全件検索となり、全文検索はできません。
ですので今回はAWSの全文検索用のサービスであるCloudSearchを使用します。
CloudSearchについては記事の内容から逸れるのでばっさり割愛しますが、全文検索の対象となる項目を定義してデータをアップロードするだけで全文検索することが可能となりますので、事前にDynamoDBのデータをCloudSearchにアップロードしておきます。
※データのアップロードは、インデックスの作成処理を行われる為データ量に応じて処理に時間がかかりますのでご注意ください。
CloudSearchの項目一覧画面

CloudSearchのデータをアップロードする画面

DynamoDBからCloudSearchへのデータのアップロードは上記のようにAWSの管理画面から実行する事が可能です、S3のファイル等もCloudSearchへアップロードする事が可能です。
また、もちろんAPI経由でのアップロードも可能ですので、前回アップロードしてから発生した差分のデータを自動的にCloudSearchにアップロードすることも恐らく可能かと思います。
これでデータの準備は完了です。続いてSalesforce側に移ります。
Connectorの実装
まずはConnectorをApexで実装します。
Connectorは下記の2クラスを実装すればOKです。
- DataSource.Connectionを継承したクラス
- DataSource.Providerを継承したクラス
それぞれのクラスがどういう役割を持っていて、どのような実装をすればよいかプログラムを通して説明します。
DataSource.Connectionを継承したクラス
DataSource.Connecionクラスを継承したクラスは外部データソースとのつなぎを担当する部分となり、主な役割は下記の3つです。
- 外部オブジェクトとして定義すべきオブジェクト名と項目定義を返す(syncメソッド)
- ビューや詳細画面表示時、またSOQL発行時に適切なデータを返す(queryメソッド)
- グローバル検索実行時、またSOQL発行時に適切なデータを返す(searchメソッド)
今回作成したクラスをサンプルとして実装内容を説明してきます。
まずはsyncメソッドからです。
当該メソッドは新規に外部データソースを作成する場合や、外部データソースの設定画面で「検証して同期」を押下時にApex Connector Frameworkから呼び出されますので、外部オブジェクトの名前と、外部オブジェクトに定義したい項目名と型や桁数を設定して返します。
override global List<DataSource.Table> sync() {
List<DataSource.Table> tables = new List<DataSource.Table>();
List<DataSource.Column> columns;
columns = new List<DataSource.Column>();
columns.add(DataSource.Column.text('title',255));
columns.add(DataSource.Column.textarea('detail'));
columns.add(DataSource.Column.text('no', 2));
columns.add(DataSource.Column.text('case_id', 8));
columns.add(DataSource.Column.text('ExternalId', 10));
columns.add(DataSource.Column.url('DisplayUrl'));
tables.add(DataSource.Table.get('Cases','case_id',columns));
return tables;
}
今回は1オブジェクトで事足りるのでDataSource.Tableを1件しか返していませんが、複数の外部オブジェクトの定義を設定して返すことも可能です。
ちなみにExternalIdとDisplayUrlの項目は必須のようで、定義しなくてもコンパイルは通りますが外部オブジェクトの作成ができませんので注意が必要です。
外部データソースの項目定義が変更になった際にsyncメソッドの内容を変更しなくてもよいように、どこか(静的リソースとか?)に項目定義を何かしらの形で保持しておいて動的に DataSource.Table を定義できるようにした方がいいのかな~
続いてqueryメソッドです。
当該メソッドは画面で外部オブジェクトのビューや参照画面を表示時、またSOQL発行時にApex Connector Frameworkから呼び出されます。
override global DataSource.TableResult query(DataSource.QueryContext c){
DataSource.Filter filter = c.tableSelection.filter;
DynamoDBClient client = new DynamoDBClient();
AWSAccessResult aar;
if (filter != null && filter.columnName != null && filter.columnName.equals('ExternalId')) {
String[] key = String.valueOf(filter.columnValue).split('-');
aar = client.getItem(
'{"TableName": "cases", "Key": {"case_id": {"S": "' + key[0] + '"},"no":{"S":"' + key[1] + '"}}}');
} else {
aar = client.scan('{"TableName": "cases"}');
}
if(!aar.isSuccess()) {
aar.outputResult();
throw new DynamoDBException('エラーですよ');
}
List<Map<String, Object>> parsedRows = parseResponse(aar.res.getBody());
List<Map<String,Object>> filteredRows =
DataSource.QueryUtils.filter(c, parsedRows);
List<Map<String,Object>> sortedRows =
DataSource.QueryUtils.sort(c, filteredRows);
List<Map<String,Object>> limitedRows =
DataSource.QueryUtils.applyLimitAndOffset(c, sortedRows);
return DataSource.TableResult.get(c, limitedRows);
}
引数で渡されるDataSource.QueryContextに条件が設定されていますので、その条件を元に外部データソースに対する検索処理を実装します。
今回はDynamoDBのAPIを直接叩くように実装しております。もし実装内容にご興味のある方はこちらに今回作成した全クラスを載せておりますのでご参照ください。
外部データソースから取得したデータは List<Map<String,Object>> に変換し、最終的に DataSource.TableResult という型で返します。
ここらへんの実装がやや泥臭くなりがちですが、DataSource.QueryUtils を使用するとソートやフィルタリング、ページング処理で少し楽ができます。
ただ DataSource.QueryUtils に頼りすぎるとガバナ制限に抵触したりパフォーマンスが悪くなる可能性が0ではないので、リソースを意識した実装が必要になると思います。
外部データソースでテーブル結合した結果をSalesforce上で参照したい場合とかは、結合した項目の定義をsyncメソッド内で設定しておいて、このqueryメソッドでゴニョゴニョすればいけそうな気がしますね・・・でも、実装が泥臭くなりそうだな・・・
最後にsearchメソッドです。
当該メソッドは画面でグローバール検索実行時、またSOSL発行時にApex Connector Frameworkから呼び出されます。
override global List<DataSource.TableResult> search(DataSource.SearchContext c){
List<DataSource.TableResult> tableResults = new List<DataSource.TableResult>();
CloudSearchClient client = new CloudSearchClient();
AWSAccessResult aar =
client.search('q=' + EncodingUtil.urlEncode(c.searchPhrase, 'UTF-8'), 'search-cases-v2hhtee7vt3frqenggaoelsrjy');
if(!aar.isSuccess()) {
aar.outputResult();
throw new CloudSearchException('エラーですよ');
}
tableResults.add(
DataSource.TableResult.get(c.tableSelections.get(0), parseResponse(aar.res.getBody())));
return tableResults;
}
searchメソッドもqueryメソッドと同様に DataSource.SearchContext が引数として渡されます。
検索文字列は SearchContextのsearchPhrase に設定されてますので、CloudSearchのAPIに渡してます。
そしてこれまたqueryメソッドと同様に取得したデータを List<Map<String,Object>> に変換して最終的に DataSource.TableResult という型で返せばOKです。
少し話は逸れますが、CloudSearchではファセット情報(カテゴリ毎の件数の集計等)が取得できて便利ですので、これまたファセット情報用の外部オブジェクトの定義を行ってsearchメソッドでゴニョゴニョすればファセット情報をSalesforceの画面に表示するのもできそうですね。
DataSource.Connection クラスはこれで完了です。
実装していて思ったのですが、Connectionクラスで外部データソースを参照せずに普通にSalesforceのオブジェクトを検索するように実装すれば、いわゆるRDBのビューなんかも実装できてしまいますね~
まあそんなことをする必要もないかと思いますし、コスト的に割に合わないとは思いますがw
続いてDataSource.Providerです。
DataSource.Providerを継承したクラス
DataSource.Providerクラスを継承したクラスは外部データソースの前提条件を定義する部分となり、外部データソースを登録、編集する画面に関連するクラスとなります。主な役割は下記の3つです。
- 外部データソースに対する認証方式を返す(getAuthenticationCapabilitiesメソッド)
- Connectorがどのアクション(SOQL、SOSL)に対応しているかを返す(getCapabilitiesメソッド)
- どのConnectionクラスを使用するかを返す(getConnectionメソッド)
まずは getAuthenticationCapabilities メソッドからです。
当該メソッドは外部データソースに対する認証方式の選択肢を返すもので、外部データソースの登録、編集画面の認証プロトコルの選択値と対応しています。
override global List<DataSource.AuthenticationCapability>
getAuthenticationCapabilities() {
List<DataSource.AuthenticationCapability> capabilities =
new List<DataSource.AuthenticationCapability>();
capabilities.add(DataSource.AuthenticationCapability.ANONYMOUS);
return capabilities;
}
今回はConnectionでAWSのV4による認証情報を付与しますので、「認証なし」のみが画面で選択肢として表示されるように実装しています。
続いてgetCapabilitiesメソッドです。
override global List<DataSource.Capability> getCapabilities() {
List<DataSource.Capability> capabilities = new List<DataSource.Capability>();
capabilities.add(DataSource.Capability.ROW_QUERY);
capabilities.add(DataSource.Capability.SEARCH);
return capabilities;
}
今回はSOQLとSOSLの両方に対応させるよう実装しています。
最後にgetConnectionメソッドです。
override global DataSource.Connection getConnection(
DataSource.ConnectionParams connectionParams) {
return new DynamoDBConnection(connectionParams);
}
使用するConnectionはもちろん上で実装したクラスとなりますね。
引数の DataSource.ConnectionParams は今回使用しませんが、外部データソースで設定した情報やOAuthのトークン等が設定されていて、DataSource.Connectionで使用する事が可能のようですね。
実装は以上となります。
割愛しますが、この後に外部データソースを新規作成すれば本記事の最初に紹介したことが可能となるはずです。
さいごに
いや~Connectorを作るって、やっぱり大変ですね。
実は今回結構手を抜いてます。
例えばDataSource.Connection のqueryの処理なんかは、DynamoDBのプライマリキーが指定されていない場合はデータを全件取得しDataSource.QueryUtils に頼りまくってデータを絞り込んでます。
本来ならばApex Connector Framework から引数で渡された条件で絞り込むようにDynamoDBのAPIを叩くべきなんですよね(DynamoDBはプライマリキーと一部列でしか検索できないので、DynamoDB側の考慮も必要なのですが・・・)
また、queryメソッドもそうなのですがsearchメソッドでもページングの処理がごっそり抜けてたりします。
もしLightning Connectの利用をご検討されている方がいらっしゃいましたら、ここは素直に来年初頭に予定されているSkyOnDemandのOData対応を待った方が無難かもしれません。
SkyOnDemandは弊社が提供するEAIツールなのですが、ODataのプロデューサー機能を追加する予定となっており、ODataに対応していない外部データソースとの仲介役を担ってくれることでしょう。
まずSalesforce⇔SkyOnDemand間はODataでやりとりできるようになる為、今回作成したようなコネクタの実装は必要なくなります。
そしてSkyOnDemand⇔外部データソース間は、SkyOnDemandで用意しているアダプタで簡単に外部データソースに接続可能ですので、最終的にSalesforceから色んな外部データソースにアクセス可能となるはずです。
SkyOnDemandのOData対応、どのような形で登場するのか個人的にとても楽しみにしております。
それにしてもLightning Connect、面白い機能だとは思うのですが、もう少しお手頃価格になったりしないんですかね~